Die meisten Workflow Engines verlangen eigene Infrastruktur. Temporal braucht einen Cluster. AWS Step Functions lockt dich an einen Cloud Provider. Selbst leichtere Alternativen wollen einen separaten Server, ein proprietäres SDK und noch ein System, das du monitoren musst.
Aber du hast schon Postgres. flowly macht daraus eine Durable Workflow Engine.
Die Idee
Du definierst Workflows als normale async Functions. Jeder Step speichert sein Ergebnis in Postgres. Wenn der Prozess crashed, setzt der Workflow beim letzten abgeschlossenen Step fort. Kein neues System, keine neue Sprache, nichts zwischen dir und node index.js.
import { defineWorkflow, DurableEngine } from "flowly";
const orderWorkflow = defineWorkflow(
"process-order",
async (ctx, input: { orderId: string; amount: number }) => {
const reserved = await ctx.step("reserve-inventory", {
run: () => inventoryService.reserve(input.orderId),
compensate: (result) => inventoryService.release(result.reservationId),
retry: { maxAttempts: 3, backoff: "exponential", initialDelayMs: 500 },
});
await ctx.sleep("cooling-period", { seconds: 30 });
const charged = await ctx.step("charge-payment", {
run: () => paymentService.charge(input.amount),
compensate: (result) => paymentService.refund(result.chargeId),
});
return { reserved, charged };
}
);Das ist kein Pseudocode. ctx.step() speichert das Ergebnis. ctx.sleep() persistiert einen Timer. Compensate-Functions laufen in umgekehrter Reihenfolge, wenn ein späterer Step fehlschlägt.
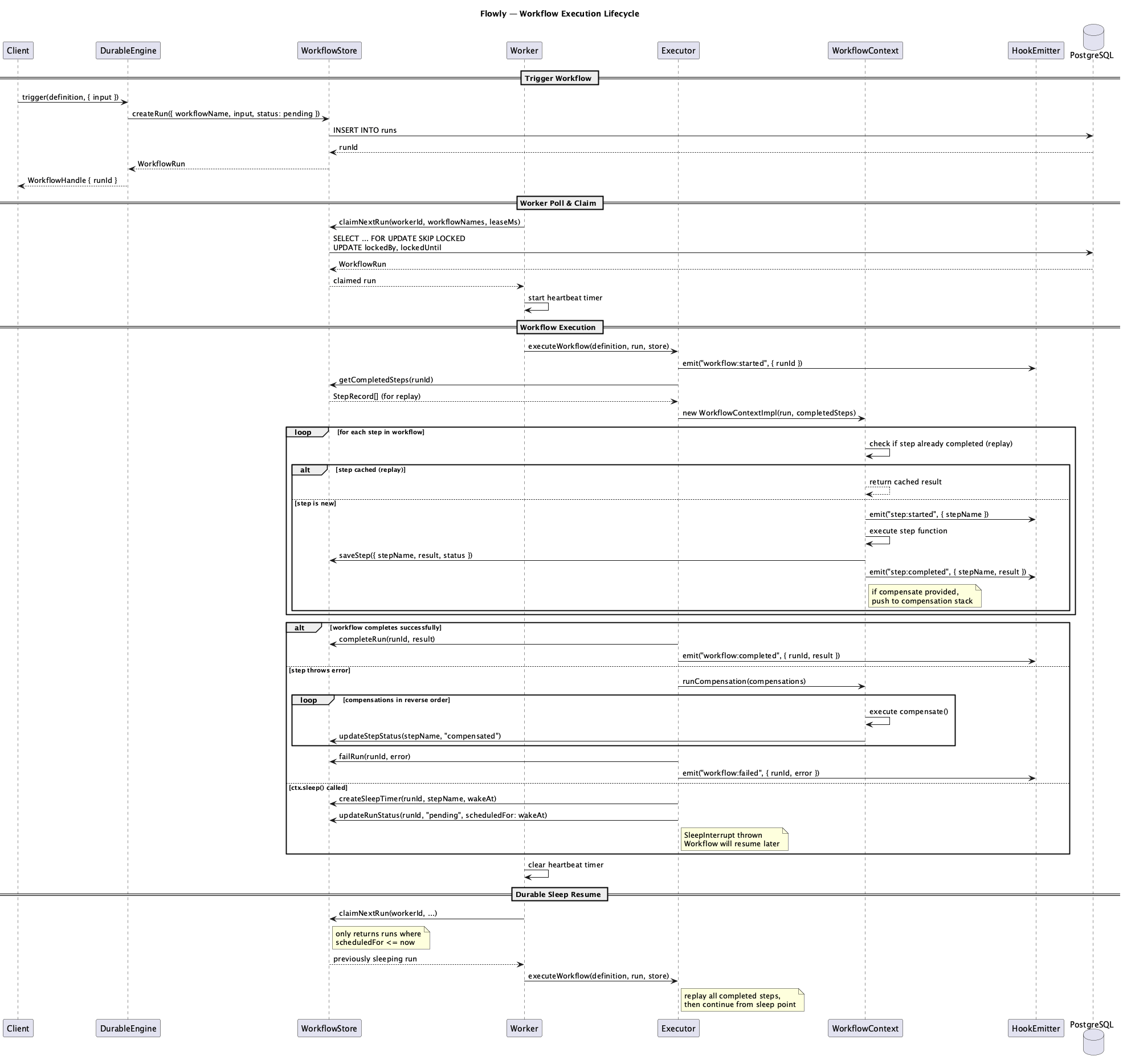
Step Persistence und Replay
Beim ersten Durchlauf führt flowly jeden Step aus und speichert das Ergebnis in Postgres. Beim Replay (nach Crash, Restart, Deployment) lädt es die gespeicherten Ergebnisse und überspringt die Ausführung. Der Workflow sieht den gleichen Return Value wie beim ersten Mal.
Die Schwierigkeit liegt im Detail: was passiert, wenn ein Step läuft, das Ergebnis in Postgres landet, aber der Prozess crashed bevor der Workflow-State aktualisiert wird? flowly nutzt ON CONFLICT DO NOTHING mit explizitem BEGIN/COMMIT auf der (workflow_run_id, step_name) Unique Constraint. Wenn ein Step bereits existiert, wird er innerhalb derselben Transaktion geladen. Keine doppelte Ausführung, egal wann der Crash passiert.
Das bedeutet: Steps müssen nicht idempotent sein. Wenn reserve-inventory beim ersten Durchlauf läuft und das Ergebnis gespeichert wird, läuft es beim Replay nicht nochmal.
Concurrency mit FOR UPDATE SKIP LOCKED
Mehrere Worker Prozesse können gleichzeitig Workflows abarbeiten. Der Kern ist ein einziges SQL Statement:
UPDATE workflow_runs
SET locked_by = $1, locked_until = now() + ($2 || ' milliseconds')::interval
WHERE id = (
SELECT id FROM workflow_runs
WHERE status IN ('pending', 'running')
AND scheduled_for <= now()
AND workflow_name = ANY($3)
AND (locked_by IS NULL OR locked_until < now())
ORDER BY scheduled_for ASC
LIMIT 1
FOR UPDATE SKIP LOCKED
) RETURNING *SKIP LOCKED verhindert Thundering Herd. Kein Advisory Locking, keine Contention. Jeder Worker greift sich den nächsten verfügbaren Run, ohne auf andere zu warten.
Lease-basiertes Heartbeat
Jeder Worker extended seinen Lease im 1/3 Intervall (30s Lease → 10s Heartbeat). Wenn ein Worker crashed, läuft der Lease ab und ein anderer Worker claimed den Run. Wenn der Heartbeat fehlschlägt (z.B. Lease von einem anderen Worker gestohlen), triggert ein AbortController den Abbruch aller In-Flight Operations:
const heartbeat = setInterval(() => {
store.extendLease(run.id, workerId, leaseMs)
.then((extended) => {
if (!extended) {
log.warn("lease lost, aborting workflow");
ac.abort();
}
});
}, Math.floor(leaseMs / 3));Kein Zombie Workflow läuft ewig. Kein Worker hält eine Lock die er nicht mehr braucht.
Saga Compensation
Wenn charge-payment fehlschlägt, muss reserve-inventory rückgängig gemacht werden. Compensations laufen in umgekehrter Reihenfolge (LIFO). Jede Compensation wird einzeln ausgeführt und ihr Status in der Datenbank persistiert. Wenn auch die Compensation fehlschlägt, geht es trotzdem weiter mit den restlichen. Am Ende meldet flowly ob alle Compensations erfolgreich waren.
Nach allen Retry-Versuchen (konfigurierbarer maxAttempts mit Exponential, Linear oder Fixed Backoff) landet der Workflow in einer Dead Letter Queue. Von dort kann er manuell untersucht und mit engine.retryDeadLetter() erneut gestartet werden.
Durable Sleep
ctx.sleep("wait", { hours: 24 }) wirft eine SleepInterrupt Exception (kein Error, ein Control Flow Mechanism). Der Timer wird in Postgres persistiert mit einem Partial Index auf wake_at WHERE NOT completed. Der Workflow wird auf pending gesetzt. Wenn der Polling Loop das nächste Mal einen Run mit abgelaufenem Timer findet, geht der Workflow weiter.
Kein setTimeout. Kein Redis. Kein separater Scheduler. Postgres ist der Scheduler. Optional: LISTEN/NOTIFY für sofortiges Aufwachen bei neuen Runs statt Polling-Intervall.
Database Schema
Vier Tabellen in einem konfigurierbaren Schema:
workflow_runs: Status, Locking (locked_by,locked_until), Scheduling (scheduled_for,timeout_at)workflow_steps: Ergebnisse (JSONB), Status, Sequence für Replay-Reihenfolgesleep_timers:wake_atmit Partial Index,completedFlagcron_schedules: Recurring Workflows mitnext_run_at
Partial Unique Index auf concurrency_key verhindert doppelte Workflows pro User, erlaubt aber Retries nach Completion. Alle Tabellennamen sind mit Quoted Identifiers gegen SQL Injection geschützt.
Graceful Shutdown
Polling stoppen → AbortController für alle In-Flight Workflows triggern → Timeout-bounded Drain (wartet auf laufende Workflows, aber nicht ewig) → Heartbeat Timer clearen. Kein Workflow wird mid-step abgebrochen ohne Notification.